Do People Like Sequel Movies?
April 23, 2019 in Tools | 5 mins read | Tagged: javascript d3 python beautifulsoup4
I am a Star Wars fan, I have to admit. Well, I am not one of those hardcore Star Wars fans that say: “Star Wars are only the original trilogy”, but still, I am a big fan. At least, I liked the second trilogy, but I wasn’t amused by the third trilogy of Star Wars, so I was curious to check how people reacted to the second trilogy.
Indeed, I found that people and movie critics didn’t like/accept them to be such as good, and the once-a-hit movie turned to get ratings as bad as 50% on movies rating websites [1].
Although the newest episodes got better in matters of ratings, we must say that all goes back to the revolution in CGI and technology.
This led me to a bigger question: “Do people really like sequels? Should production companies stop when they have a hit movie, or they should keep producing sequels?”.
To answer this question, I had to use my experience in programming and work on this long project to find out. The project is called “Sequel Movies Meter”.
The project consisted of many steps as below:
Finding Movies with Sequels
Tools: Manual work.
I started looking for lists that list movies with sequels, but I wasn’t lucky in finding a good list, so I merged many lists of movies sequels.
The final list contained about 1,700 movies in 344 franchises, e.g. the franchise Star Wars contains 9 movies.
Since movies’ titles were just strings (text), I couldn’t do anything on them, because I wanted an ID for each movie.
The next step was to figure out this unique ID for each movie.
Identifying Movies
Tools: Manual work with some Python help.
After some research, I found that IMDb has more data than any of the other websites for all movies.
I used this piece of info to get a unique ID for each movie, which was the IMDb link to the movie.
I ended up adding the IMDb link for each movie to the list of the movies that I had.
Crawling Data
Tools: Beautifulsoup, Requests, URLlib, JSON, vanilla Python, and other Python tools.
I created a tool (Movie Info Finder) as an API that crawls the websites in the following order:
- Crawls the IMDb page of the movie and gets movie full name, year, and IMDb rating.
- Searches for the movie on Metacritic using the movie name, and finds the exact movie from the search results by matching the year it got from IMDb, with the year next to the movie name on Metacritic.
- Gets the link to the movie page, and crawls it for the MC critics rating and the MC users rating.
- Uses the same MC process with Rotten Tomatoes.
- Returns a JSON object for the full movie.
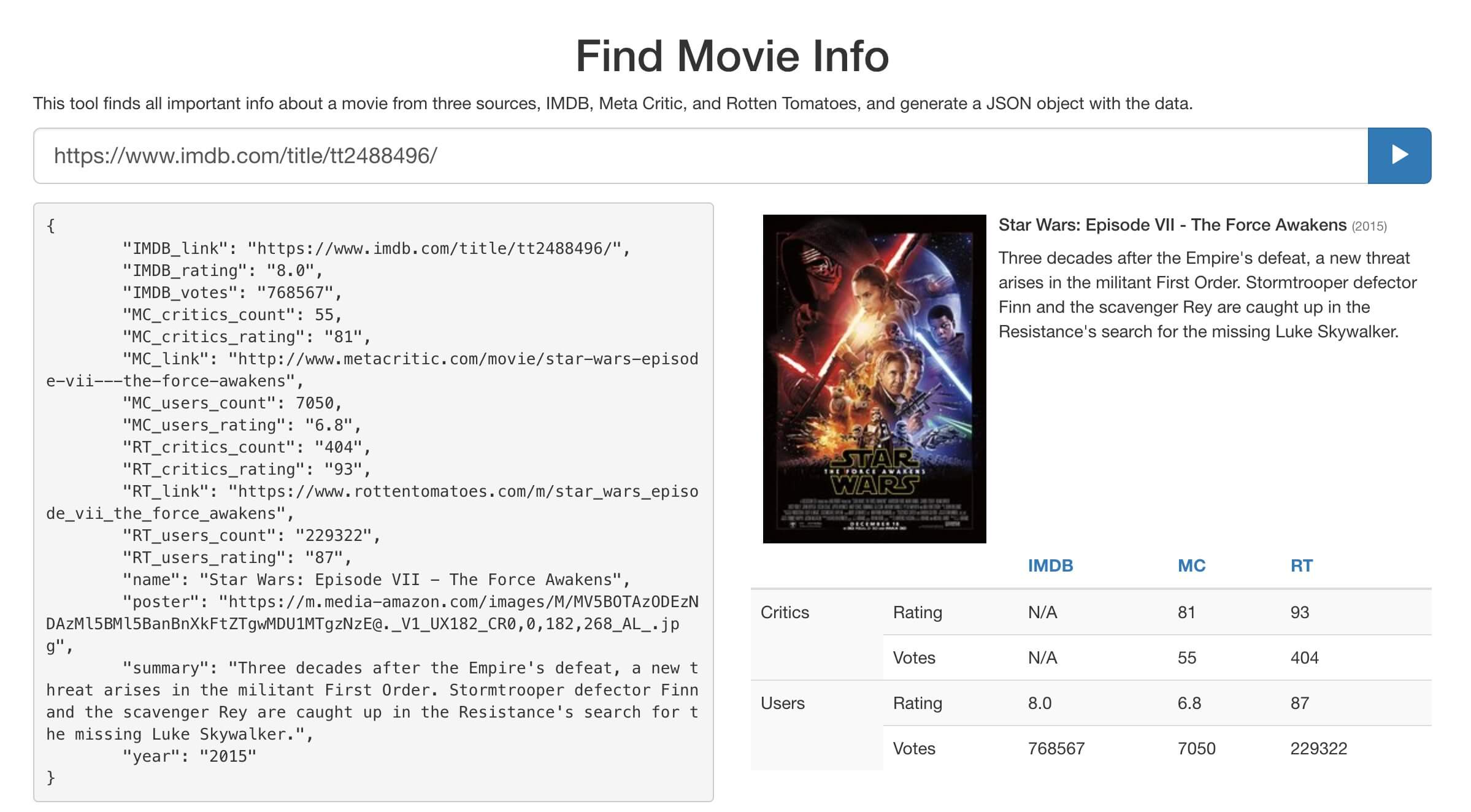
I looped on the movies list that I have with this tool and got a large JSON file that contained all movies with their data.
Building this tool was challenging as it uses a preliminary process which was time-consuming, and on top of that, Rotten Tomatoes changed their website when I finished building the tool, so I had to rebuild that part.
The tool is not as smart as I wanted, but it does the job slowly.
Sorting Movies under Franchise
Tools: JSON, DiffLib: SequenceMatcher, vanilla Python, and manual work.
Since I had no way to know that a movie name is under a franchise, I had to overcome this problem.
Using python and SequenceMatcher module from Diff Lib, I looped over the JSON file that I have and tried as much as possible to match movies names under a single franchise.
The tool did almost 70% of the work, but then I had to check each movie manually to be sure of the results and fix the errors.
Building the Charts
Tools: JSON, D3JS Version 4, HTML, and CSS.
“What’s better than data, graph data”
I had a very good JSON with all movies and their data sorted by the franchise, but who likes to read?
I started using D3JS to build a multiple line chart to show all the data of the movies on a single page, which helped reading the data in just a glance on the charts.
Yet the charts were noisy with all the data on them.
Reducing the Noise
Tools: Python, JSON, D3JS Version 4, HTML, and CSS.
To remove noise from the charts, I decided to have two lines for each movie, one for the critics from all the websites, and the second is for the users of the websites.
Using Python, I looped on the JSON file calculating a score for each movie by summing the data.
The final result seems perfect.
Results
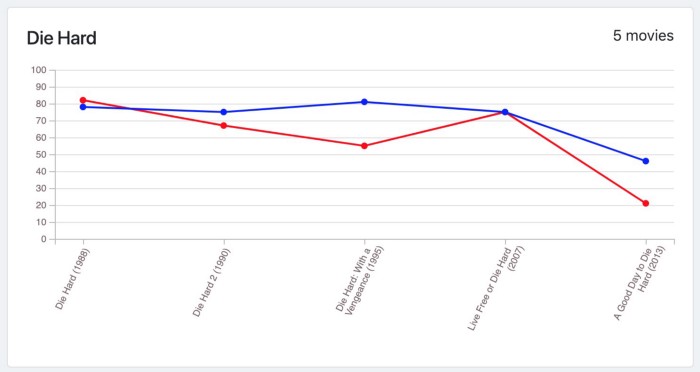
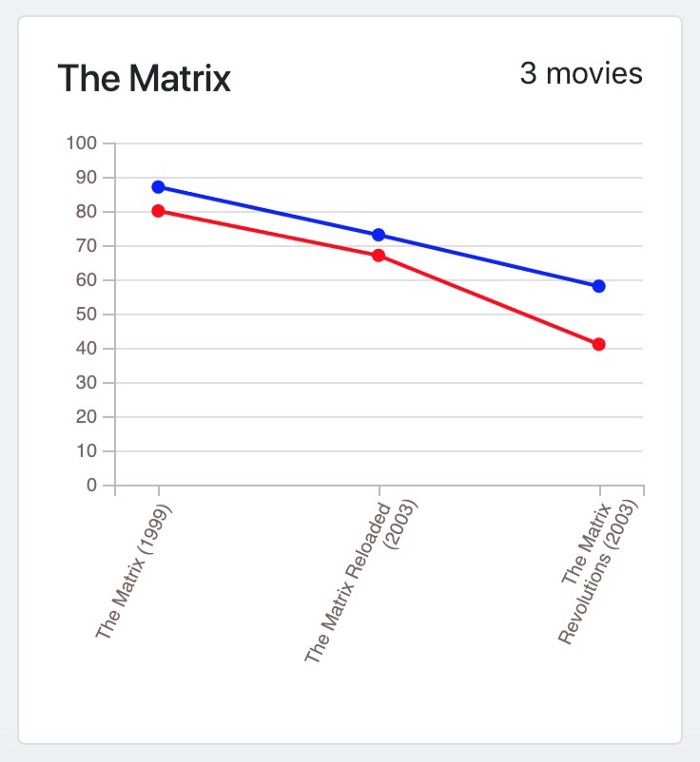
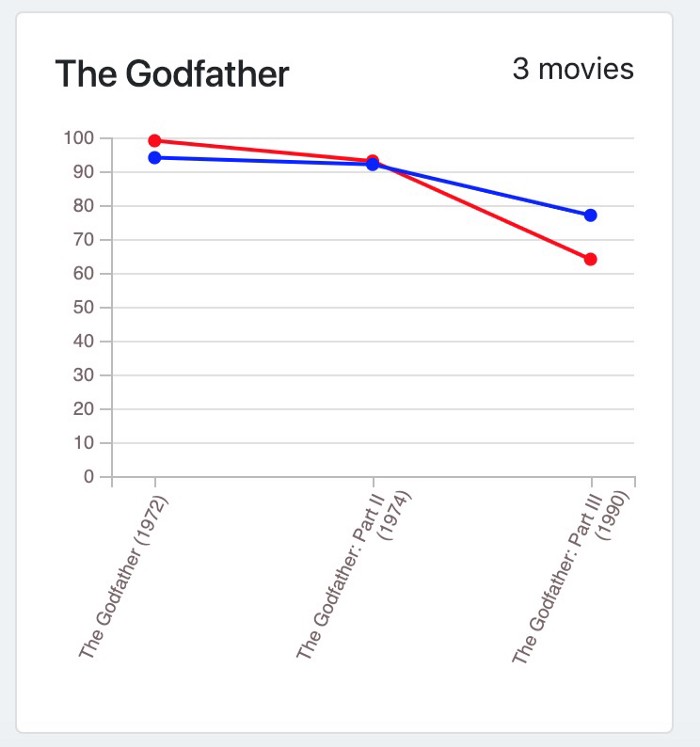
Despite the fact that a movie like “The Lord of the Rings” has a consistent rating for the trilogy (because it wasn’t first written and produced to be a trilogy), apparently, the answer to my question was: People don’t usually like sequels, production companies should really stop at the first movie.
Examples from the meter for popular movies:
Final Thoughts
Working on this project was interesting and mentally challenged me to get the results.
I hope everyone likes this page (Sequel Movie Meter) and finds it useful for something.
[1] IMDb, Rotten Tomatoes, and Metacritic. These three websites provide five ratings: IMDb users, Metacritic critics, Metacritic users, Rotten Tomatoes critics, and Rotten Tomatoes users.